Bus Arbitration
Bus Arbitration refers to the process by which the current bus master accesses and then leaves the control of the bus and passes it to another bus requesting processor unit. The controller that has access to a bus at an instance is known as a Bus master.
A conflict may arise if the number of DMA controllers or other controllers or processors try to access the common bus at the same time, but access can be given to only one of those. Only one processor or controller can be Bus master at the same point in time. To resolve these conflicts, the Bus Arbitration procedure is implemented to coordinate the activities of all devices requesting memory transfers. The selection of the bus master must take into account the needs of various devices by establishing a priority system for gaining access to the bus. The Bus Arbiter decides who would become the current bus master.
There are two approaches to bus arbitration:
- Centralized bus arbitration –
A single bus arbiter performs the required arbitration.
- Distributed bus arbitration –
All devices participating in the selection of the next bus master.
Methods of Centralized BUS Arbitration:
There are three bus arbitration methods:
(i) Daisy Chaining method: It is a simple and cheaper method where all the bus masters use the same line for making bus requests. The bus grant signal serially propagates through each master until it encounters the first one that is requesting access to the bus. This master blocks the propagation of the bus grant signal, therefore any other requesting module will not receive the grant signal and hence cannot access the bus.
During any bus cycle, the bus master may be any device – the processor or any DMA controller unit, connected to the bus.

Advantages:
- Simplicity and Scalability.
- The user can add more devices anywhere along the chain, up to a certain maximum value.
Disadvantages:
- The value of priority assigned to a device depends on the position of the master bus.
- Propagation delay arises in this method.
- If one device fails then the entire system will stop working.
(ii) Polling or Rotating Priority method: In this, the controller is used to generate the address for the master(unique priority), the number of address lines required depends on the number of masters connected in the system. The controller generates a sequence of master addresses. When the requesting master recognizes its address, it activates the busy line and begins to use the bus.

Advantages –
- This method does not favor any particular device and processor.
- The method is also quite simple.
Disadvantages –
- Adding bus masters is difficult as increases the number of address lines of the circuit.
- If one device fails then the entire system will not stop working.
(iii) Fixed priority or Independent Request method –
In this, each master has a separate pair of bus request and bus grant lines and each pair has a priority assigned to it.
The built-in priority decoder within the controller selects the highest priority request and asserts the corresponding bus grant signal.
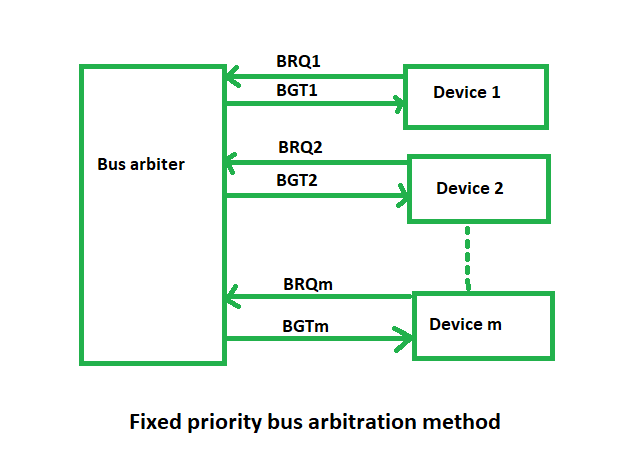
Advantages –
- This method generates a fast response.
Disadvantages –
- Hardware cost is high as a large no. of control lines is required.
Distributed BUS Arbitration :
In this, all devices participate in the selection of the next bus master. Each device on the bus is assigned a 4bit identification number. The priority of the device will be determined by the generated ID.
Set Associative Cache Mapping
Set-associative Mapping –
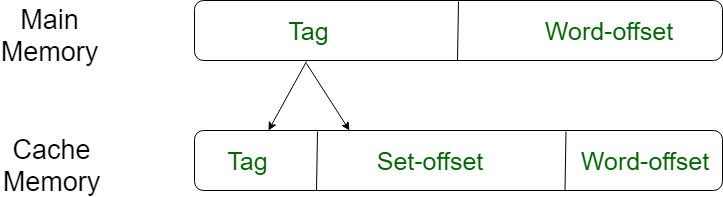
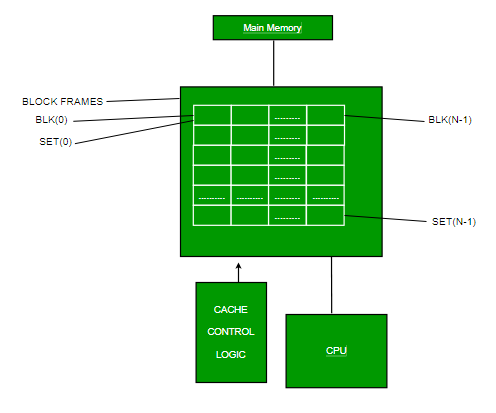
This form of mapping is an enhanced form of direct mapping where the drawbacks of direct mapping are removed. Set associative addresses the problem of possible thrashing in the direct mapping method. It does this by saying that instead of having exactly one line that a block can map to in the cache, we will group a few lines together creating a set. Then a block in memory can map to any one of the lines of a specific set..Set-associative mapping allows that each word that is present in the cache can have two or more words in the main memory for the same index address. Set associative cache mapping combines the best of direct and associative cache mapping techniques.
In this case, the cache consists of a number of sets, each of which consists of a number of lines. The relationships are
m = v * k
i= j mod v
where
i=cache set number
j=main memory block number
v=number of sets
m=number of lines in the cache number of sets
k=number of lines in each set
Application of Cache Memory –
- Usually, the cache memory can store a reasonable number of blocks at any given time, but this number is small compared to the total number of blocks in the main memory.
- The correspondence between the main memory blocks and those in the cache is specified by a mapping function.
Types of Cache –
- Primary Cache –
A primary cache is always located on the processor chip. This cache is small and its access time is comparable to that of processor registers. - Secondary Cache –
Secondary cache is placed between the primary cache and the rest of the memory. It is referred to as the level 2 (L2) cache. Often, the Level 2 cache is also housed on the processor chip.
Locality of reference –
Since size of cache memory is less as compared to main memory. So to check which part of main memory should be given priority and loaded in cache is decided based on locality of reference.
Types of Locality of reference
- Spatial Locality of reference
This says that there is a chance that element will be present in the close proximity to the reference point and next time if again searched then more close proximity to the point of reference. - Temporal Locality of reference
In this Least recently used algorithm will be used. Whenever there is page fault occurs within a word will not only load word in main memory but complete page fault will be loaded because spatial locality of reference rule says that if you are referring any word next word will be referred in its register that’s why we load complete page table so the complete block will be loaded.
Tirthankar Pal
MBA from IIT Kharagpur with GATE, GMAT, IIT Kharagpur Written Test, and Interview
2 year PGDM (E-Business) from Welingkar, Mumbai
4 years of Bachelor of Science (Hons) in Computer Science from the National Institute of Electronics and Information Technology
Google and Hubspot Certification
Brain Bench Certification in C++, VC++, Data Structure and Project Management
10 years of Experience in Software Development out of that 6 years 8 months in Wipro
Selected in Six World Class UK Universities:-
King's College London, Durham University, University of Exeter, University of Sheffield, University of Newcastle, University of Leeds




















_page-0001.jpg)









_page-0001.jpg)







PLC Consulting - 1 year 4 months
Aircom International - 2 years 2 months
Wipro Technologies - 6 years 8 months
A total of 10 years and 2 months.
Exceptional Talent as given by my managers and shown in my appraisals. All my appraisals are uploaded in www.palsedutech.com
My last salary - Rs. 7.31 lakhs p.a. 😉 😉
From 2013 till date I COULD NOT GET A JOB. Fantastic.
My students have got into IIT Kharagpur, NIT Durgapur, 90% plus in CBSE, ICSE, B.Sc Computer Science.
Wow and I still did not get a JOB.