A graph can be represented using 2 data structures- adjacency matrix and adjacency list
An adjacency matrix can be thought of as a table with rows and columns. The row labels and column labels represent the nodes of a graph. An adjacency matrix is a square matrix where the number of rows, columns and nodes are the same. Each cell of the matrix represents an edge or the relationship between two given nodes. For example, adjacency matrix Aij represents the number of links from i to j, given two nodes i and j.
For example, adjacency matrix Aij represents the number of links from i to j, given two nodes i and j.
| A | B | C | D | E | |
| A | 0 | 0 | 0 | 0 | 1 |
| B | 0 | 0 | 1 | 0 | 0 |
| C | 0 | 1 | 0 | 0 | 1 |
| D | 1 | 0 | 0 | 1 | 0 |
| E | 0 | 1 | 1 | 0 | 0 |
The adjacency matrix for a directed graph is shown in Fig 3. Observe that it is a square matrix in which the number of rows, columns and nodes remain the same (5 in this case). Each row and column correspond to a node or a vertex of a graph. The cells within the matrix represent the connection that exists between nodes. Since, in the given directed graph, no node is connected to itself, all cells lying on the diagonal of the matrix are marked zero. For the rest of the cells, if there exists a directed edge from a given node to another, then the corresponding cell will be marked one else zero.

To understand how an undirected graph can be represented using an adjacency matrix, consider a small undirected graph with five vertices (Fig 4). Here, A is connected to B, but B is connected to A as well. Hence, both the cells i.e., the one with source A destination B and the other one with source B destination A are marked one. This suffices the requirement of an undirected edge. Observe that the second entry is at a mirrored location across the main diagonal.

In case of a weighted graph, the cells are marked with edge weights instead of ones. In Fig 5, the weight assigned to the edge connecting nodes B and D is 3. Hence, the corresponding cells in the adjacency matrix i.e. row B column D and row D column B are marked 3.

NetworkX library provides an easy method to create adjacency matrices. The following example shows how we can create a basic adjacency matrix using NetworkX.

In adjacency list representation of a graph, every vertex is represented as a node object. The node may either contain data or a reference to a linked list. This linked list provides a list of all nodes that are adjacent to the current node. Consider a graph containing an edge connecting node A and node B. Then, the node A will be available in node B’s linked list. Fig 6 shows a sample graph of 5 nodes and its corresponding adjacency list.
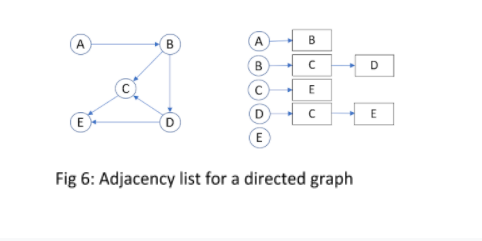
Note that the list corresponding to node E is empty while lists corresponding to nodes B and D have 2 entries each.
Similarly, adjacency lists for an undirected graph can also be constructed. Fig 7 provides an example of an undirected graph along with its adjacency list for better understanding.

Adjacency list enables faster search process in comparison to adjacency matrix. However, it is not the best representation of graphs especially when it comes to adding or removing nodes. For example, deleting a node would involve looking through all the adjacency lists to remove a particular node from all lists.
Tirthankar Pal
MBA from IIT Kharagpur with GATE, GMAT, IIT Kharagpur Written Test, and Interview
2 year PGDM (E-Business) from Welingkar, Mumbai
4 years of Bachelor of Science (Hons) in Computer Science from the National Institute of Electronics and Information Technology
Google and Hubspot Certification
Brain Bench Certification in C++, VC++, Data Structure and Project Management
10 years of Experience in Software Development out of that 6 years 8 months in Wipro
Selected in Six World Class UK Universities:-
King's College London, Durham University, University of Exeter, University of Sheffield, University of Newcastle, University of Leeds














![value at location [mid] = 25](https://www.softwaretestinghelp.com/wp-content/qa/uploads/2020/03/6-2.png)




