Latency
Memory latency and memory access times are used interchangeably many times, however, they are different in certain cases and depends on the type of memory under consideration.
However, I believe we can go with below definitions for being generic.
Memory latency : The time taken for accessing a memory starting from making a request to getting the data.
Memory access (Average memory access) : It refers to the *average time taken for accessing a memory starting from making a request for getting the data.
*Average time taken = mean time taken in different memory access which includes hits/misses/fails for a request to memory
What Is Bandwidth?
Bandwidth refers to the amount of data that can be transmitted and received during a specific period of time. For instance, if a network has high bandwidth, this means a higher amount of data can be transmitted and received.
Like throughput, the unit of measurement for bandwidth is bits per second (bps). Bandwidth can also be measured in gigabits per second (Gbps) and megabits per second (Mbps). High bandwidth doesn’t necessarily guarantee optimal network performance. If, for example, the network throughput is being impacted by packet loss, jitter, or latency, your network is likely to experience delays even if you have high bandwidth availability.
Sometimes, bandwidth is confused with speed, but this is a widespread misconception. Bandwidth measures capacity, not speed. This misconception is often perpetuated by internet service providers peddling the idea that high-speed services are facilitated by maximum bandwidth availability. While this may make for a convincing advertisement, high bandwidth availability doesn’t necessarily translate into high speeds. In fact, if your bandwidth is increased, the only difference is a higher amount of data can be transmitted at any given time. Although the ability to send more data might seem to improve network speeds, increasing bandwidth doesn’t increase the speed of packet transmission.
In reality, bandwidth is one of the many factors that contribute to network speed. Speed measures response time in a network, and response time will also be impacted by factors like latency and packet loss rates.
Memory Cycle time
It is the total time that is required to store next memory access operation from the previous memory access operation. Memory cycle time = access time plus transient time (any additional time required before a second access can commence). — Time may be required for the memory to “recover” before next access — Cycle time is access + recovery
Differentiate between Programmed driven I/O and Interrupt driven I/O
Data transfer between the CPU and I/O devices can be done in variety of modes. These are three possible modes:
- Programmed I/O
- Interrupt initiated I/O
- Direct Memory Access (DMA)
In this article we shall discuss the first two modes only.
1. Programmed I/O :
In this mode the data transfer is initiated by the instructions written in a computer program. An input instruction is required to store the data from the device to the CPU and a store instruction is required to transfer the data from the CPU to the device. Data transfer through this mode requires constant monitoring of the peripheral device by the CPU and also monitor the possibility of new transfer once the transfer has been initiated. Thus CPU stays in a loop until the I/O device indicates that it is ready for data transfer. Thus programmed I/O is a time consuming process that keeps the processor busy needlessly and leads to wastage of the CPU cycles.
This can be overcome by the use of an interrupt facility. This forms the basis for the Interrupt Initiated I/O.
2. Interrupt Initiated I/O :
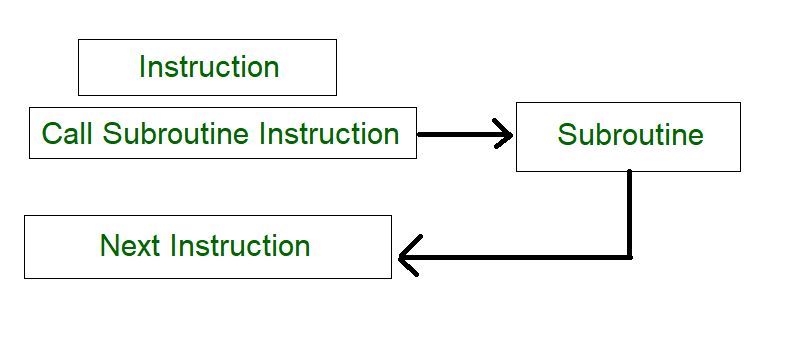
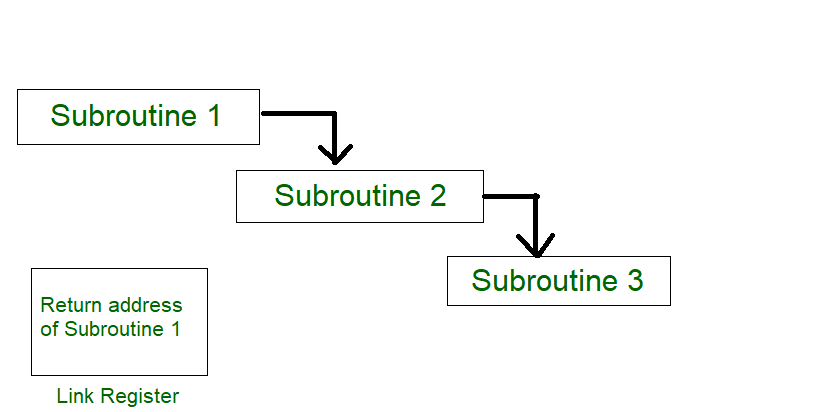
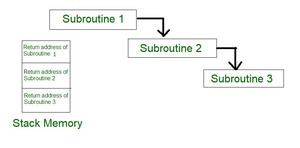
This mode uses an interrupt facility and special commands to inform the interface to issue the interrupt command when data becomes available and interface is ready for the data transfer. In the meantime CPU keeps on executing other tasks and need not check for the flag. When the flag is set, the interface is informed and an interrupt is initiated. This interrupt causes the CPU to deviate from what it is doing to respond to the I/O transfer. The CPU responds to the signal by storing the return address from the program counter (PC) into the memory stack and then branches to service that processes the I/O request. After the transfer is complete, CPU returns to the previous task it was executing. The branch address of the service can be chosen in two ways known as vectored and non-vectored interrupt. In vectored interrupt, the source that interrupts, supplies the branch information to the CPU while in case of non-vectored interrupt the branch address is assigned to a fixed location in memory.
| Programmed I/O | Interrupt Initiated I/O |
|---|---|
| Data transfer is initiated by the means of instructions stored in the computer program. Whenever there is a request for I/O transfer the instructions are executed from the program. | The I/O transfer is initiated by the interrupt command issued to the CPU. |
| The CPU stays in the loop to know if the device is ready for transfer and has to continuously monitor the peripheral device. | There is no need for the CPU to stay in the loop as the interrupt command interrupts the CPU when the device is ready for data transfer. |
| This leads to the wastage of CPU cycles as CPU remains busy needlessly and thus the efficiency of system gets reduced. | The CPU cycles are not wasted as CPU continues with other work during this time and hence this method is more efficient. |
| CPU cannot do any work until the transfer is complete as it has to stay in the loop to continuously monitor the peripheral device. | CPU can do any other work until it is interrupted by the command indicating the readiness of device for data transfer |
| Its module is treated as a slow module. | Its module is faster than programmed I/O module. |
| It is quite easy to program and understand. | It can be tricky and complicated to understand if one uses low level language. |
| The performance of the system is severely degraded. | The performance of the system is enhanced to some extent. |
Tirthankar Pal
MBA from IIT Kharagpur with GATE, GMAT, IIT Kharagpur Written Test, and Interview
2 year PGDM (E-Business) from Welingkar, Mumbai
4 years of Bachelor of Science (Hons) in Computer Science from the National Institute of Electronics and Information Technology
Google and Hubspot Certification
Brain Bench Certification in C++, VC++, Data Structure and Project Management
10 years of Experience in Software Development out of that 6 years 8 months in Wipro
Selected in Six World Class UK Universities:-
King's College London, Durham University, University of Exeter, University of Sheffield, University of Newcastle, University of Leeds